To support our growth and operational requirements, we decided to change the database technology that underpins our SuperCore™ platform. After moving a thousand databases and tens of thousands of database-client services with 100% accuracy, we are close to completing the migration programme.
The database migration project has been very complex. Anyone involved will tell you that we faced many hurdles along the way, and we had to be resilient to achieve success. Without executive and cross-organizational buy-in, any change program has a low chance of success. Therefore, maintaining project commitment across 10x was crucial.
Data accuracy and project success
When transferring and processing big data, a nearly exact copy (say 99.999% accurate) is often good enough. This level of accuracy is sufficient for datasets used for statistical analysis, for example. It's much simpler and cheaper for the copy to be almost correct than to be 100% identical. For financial transaction data, which we process at 10x, it must be completely identical. Achieving that extra 0.001% is complicated. And even harder to prove.
Data integrity failure modes
Streaming data from source to target is fast and straightforward. The challenge is, how would we know if we'd received it all? We had to prove that
- We emitted all data from the source
- We transferred everything from source to target
- We wrote everything we received to the target
- We hadn't altered the data a single bit during the process.
I'll refer to these four points throughout this piece, as we used these principles to guide us when overcoming challenges throughout the project. The callouts in the diagram below illustrate how migration can compromise data integrity.
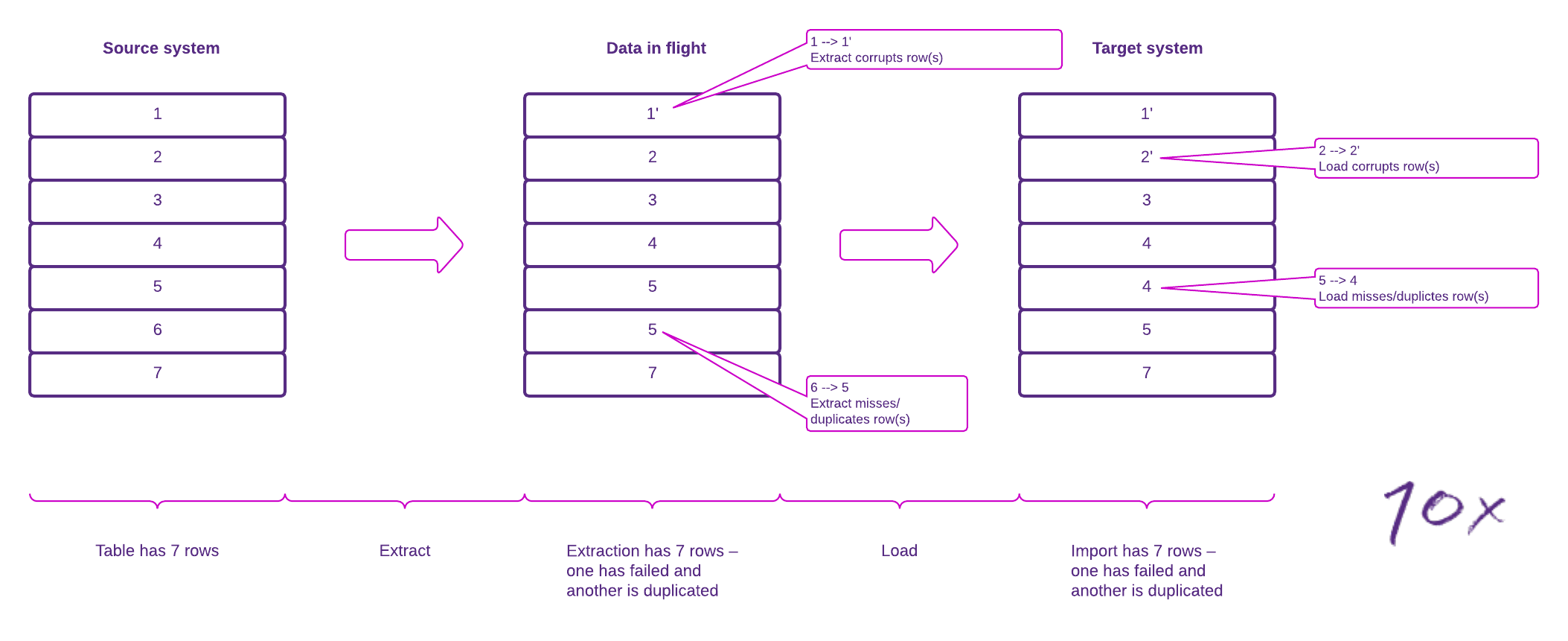 Figure 1 – Migration integrity failure modes
Figure 1 – Migration integrity failure modes
The project was made more complex by the needed to plan for these failure modes while our systems were still live and processing production workloads.
Solutions we explored
Off-the-shelf migration tools, or Extract Transform Load (ETL) tools like Azure Data Factory or AWS Database Migration Service, were our first port of call. This approach might be sufficient if your source and target are technically identical (e.g., on-prem Postgres v12 to AWS Aurora Postgres v12). However, since our source and target weren't identical, we needed to prove we hadn't altered the data during the process (D). This limited the off-the-shelf options available to us.
Next, we looked to create an event streaming pipeline of multiple off-the-shelf solutions. Several mature event streaming technologies give assurance for B (we transferred everything from source to target). Plus, there are native or extension-based event stream publishing and consumption capabilities for established technologies like Kafka. This adds counting and failure handling to the solution to cover A (We emitted all data from the source) and C (we wrote everything we received to the target). If you string these functions together, you can generate counts of data elements processed at each stage and know that no errors were flagged. However, this approach still needed to prove that we hadn't altered the data during the process (D).
While evaluating solutions, we came across these problem scenarios:
- The off-the-shelf migration solution silently reduced the precision of a datatype
- Source and target databases have different
- Precisions for datatype representations
- Special character (UTF) treatments
- JSON blob representations.
If you're lucky, behaviors like this cause the import to fail, giving you a clear error to resolve in one way or another. However, as we saw in more than one case, the process can succeed even though the data on the target end was different. The only way to reliably eliminate these errors was to prove that we hadn't altered the data a single bit during migration (D).
The 10x solution
To tackle this, we set ourselves a very high bar for success. We performed three independent verifications to ensure the source and target data were identical.
- Every data item extracted from the source had a checksum generated by the source system, included inline by the extracted data. Upon import, the target recomputed the checksum for the data item from the imported data and compared the two checksums. This proved the data item was the same but did not prove whether or not we'd lost data items during the process.
- Upon extraction, every table was checksummed by the source system and then again by the target system after import. The checksums were then compared, proving that the table was an exact copy at that point in time.
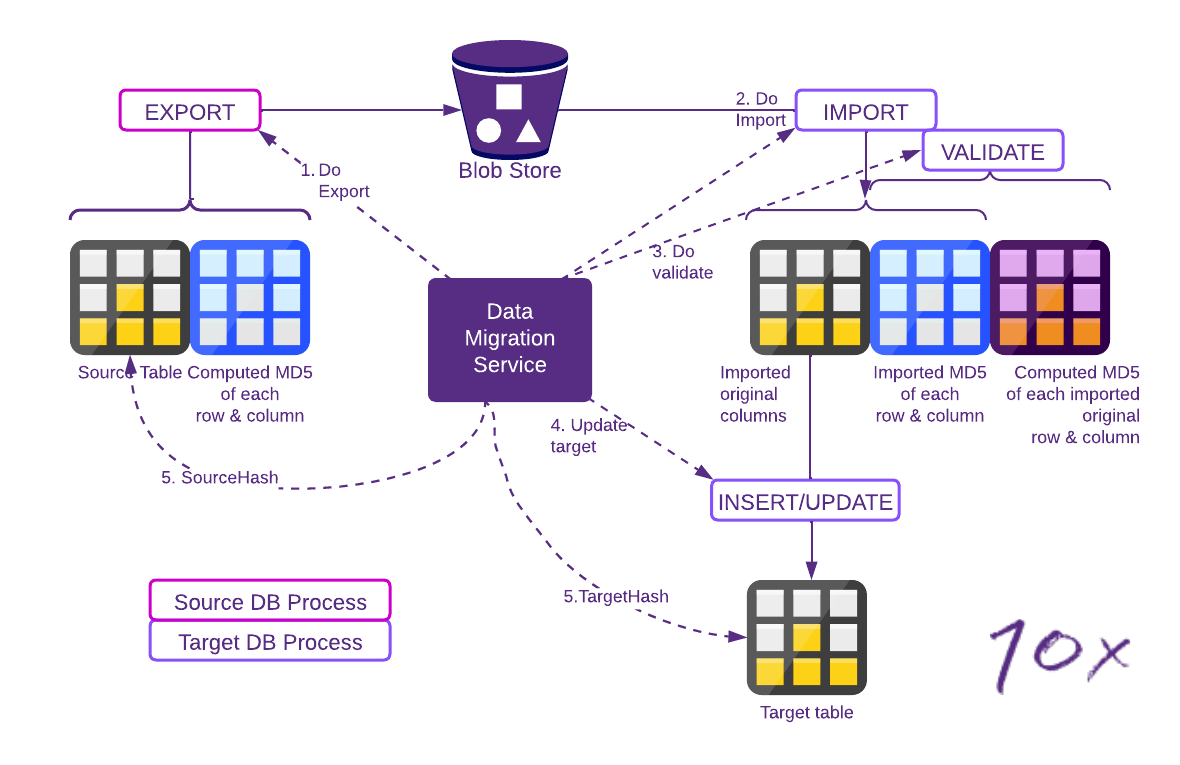
Figure 2 -Verification during data transfer
In this process, the steps are:
- Do Export - Export the table using an SQL statement that makes the source database generate a checksum for every column, for every row, and include those checksums with the exported data
- Do Import - Import the export to a staging table, including the side-car checksum pseudo columns the source generated in its export
- Do Validate - Run a SQL statement on the target staging table that recomputes the checksum for each row and column, and compare the target computed checksums to the imported checksums
- Update Target - Update the final target table from the staging table, dropping the checksums
- Source/ Target Hash – Generate a hash (checksum of row checksums) on the source and target and compare the hashes.
Logically, that is sufficient proof. But only provided the tooling itself and the checksum application logic have no bugs that leads to incorrectly asserting equality. For belt and braces security, we added another layer of verification. We developed a separate system outside the pipeline to read every migrated table from both the source and target system row-by-row and compared every field.
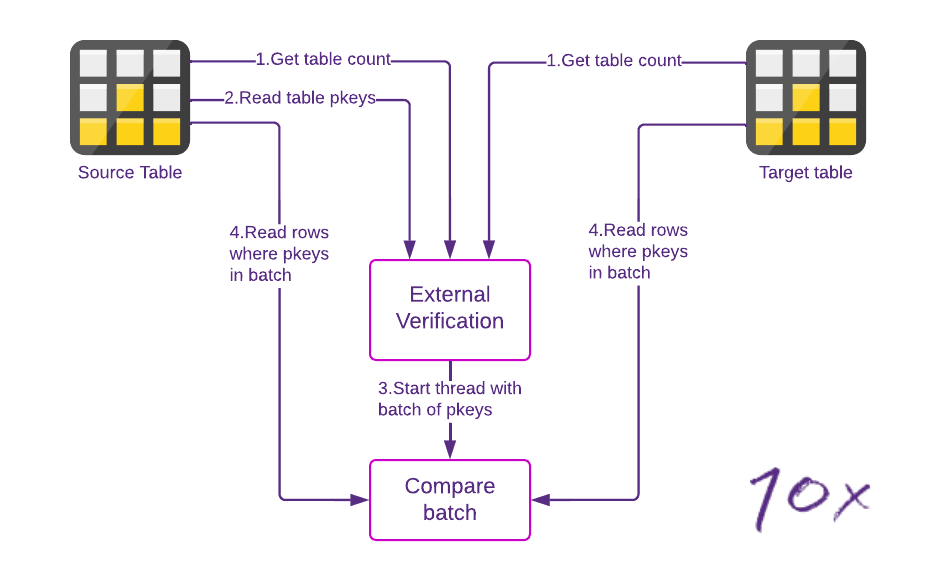
Figure 3 – Verification of target vs. source
The external verification steps, shown in this diagram, are:
- Count the rows in the table on the source and target
- Read primary keys from one database (it doesn't matter whether this is source or target, but only one side1)
- Batch up the primary read keys (for example, into blocks of 100) and start a thread to read those keys from the other database, and compare the data for the keys in a batch
- Count the number of rows in the source and target using a query that specifies the batch's primary keys. Read those rows entirely from both the source and target. Compare the read rows.
1At this point, we know both source and target tables have the same number of rows. So we only need to read primary keys from one database and look for matches in the other database in one direction to prove the two tables are or aren't identical.
Scaling the solution
At this stage, we had defined a logically safe migration system. So far, so good. The remaining challenge was to run this system on production databases across billions of rows and keep service outages to an absolute minimum. The key source capabilities that made this possible are common in modern database technologies – timeshift queries and system-managed row-level modification timestamps.
These two capabilities allowed us to extract the data from modified tables only during a specific period. This meant we could do an initial copy of the data with the above integrity checks, which took many hours in some cases, and then process deltas, which was much quicker. Also, this meant that only the last delta had to run during an outage cutover window.
Deletes
So now we have a solution that keeps the target in sync. But it has a limitation – it doesn't handle deletes to the source. Ideally, we'd have used a combination of timeshift queries to return a set of primary keys in the table at source but no longer present at target. We could then use this to remove rows from the target. But unfortunately, our source database did not support this.
As a result, we handled deletes by doing a full resync. For this, we only needed to extract the current set of primary keys rather than the entire row. We could then remove rows from the target.
Doing a full primary key resync to handle deletes was slow, so we avoided deletes during migration wherever possible. There are two uses for deletes:
- Lifecycle maintenance – deleting aged-out data
- Business logic – removing data as part of an application logic flow.
The first case was much more prevalent, and our solution was to suspend it during the migration process. We didn't need to recover deletes for those tables. The second case was rare since it was typically the result of poor schema design.
Foreign keys
Foreign key constraints mean that referenced data must be present before the reference to that data can be inserted. Therefore, a migration system must understand the foreign key constraints and sequence the updates to the target tables so that referred-to data always lands first.
This would have slowed down the import process and required complex sequencing. To avoid this, we removed all foreign key constraints from the target at the start of the migration and reinstated them at the end. Tables could be updated asynchronously, with only the final state being critical.
Sequences
Since we built the schema as code, the next value for sequences on the target (after inserting data from the source) would be reset. This would conflict with the application's expected sequence behavior and could cause uniqueness problems. We added an extra step into our final delta migration to avoid this. It read the last sequence value from the source and updated the target sequence to continue from that point.
No changes inflight
The other important decision we made for performance and data integrity reasons was that no system would interact with the data in transit. What we exported from the source was exactly what we imported into the target. Any data manipulation requirement had to be satisfied by either the way the source presented the extracted data or the target interpreted the imported data.
Solution components
To enable this process to work across the hundreds of databases in our solution, we leveraged 10x's well-established immutable schema change sets as code to build source and target schemas that matched. We developed another tool that scanned the schema from both databases and ensured it was consistent as a migration prerequisite. This same tool, which knew the schema, acted as the brain of the migration, dynamically generating all the SQL statements for both source and target systems to perform the extract, import, and verification steps.
Orchestrating the thousands of SQL statements needed across the hundreds of tables and databases led us to create an orchestration system whose job was to sequence the steps and obtain and run the SQL. Given the need to process this quickly and to avoid affecting the performance of the live system, this orchestration was a careful balancing act that required complex state machines and management of concurrency and sequencing.
For orchestrating the data migration, we considered a table as the unit of work. This meant that stages of the export and import processes could run at their own speed, governed by the size and complexity of the table, rather than being constrained by the slowest entity in the database.
Result
The result of this complex program for our clients and their customers? Absolutely nothing – they saw no change at all. But it positions the platform to continue scaling in the future, moving toward our ambition at 10x to serve one billion banking customers globally.
Conclusion
Data migration projects are an extremely complex undertaking that have a broad organizational impact. Getting these projects right is challenging, but I'm delighted that we finished successfully. Hopefully, this blog gives some insight into the technical challenges we faced and how we achieved success.