.png)
Why we can't overlook non-technical requirements
Building a platform that can scale up to serve a billion global customers for any client isn’t easy. And when those clients are reputable banks, and the platform is designed to handle real money, it’s near impossible to do so without focusing on customer security.
Here at 10x, we place great importance on ensuring our platform is safe and secure for our customers. That's why we have several teams dedicated to making this possible. Our Customer Screening team, for instance, works to validate that only those users with legitimate proof of identity can open a bank account. To achieve this, we perform a set of pre-flight checks for each user during the onboarding process to confirm that:
- We are dealing with a real-life person
- There are no illegal activities
- Occupation-related risks are mitigated (i.e. bribery prevention)
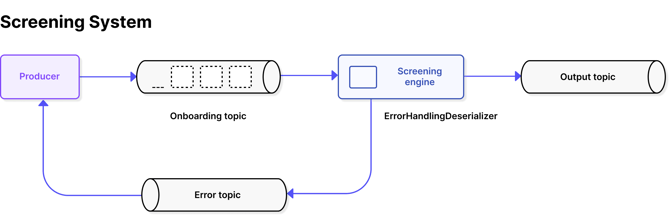
This is managed by building a Screening Engine – a system that reacts to events read from a Kafka Topic. And for each event, it conducts mandatory security checks. The goal is to ensure the process is smooth and transparent, but also set up to react in a timely fashion if misuse is detected.
3.png?width=661&name=Screening%20System%20(Sml)3.png)
Because of this, it’s crucial the system is highly reliable because onboarding should be fast and should work every single time for every customer. If something goes wrong, it may cause reputational damage, and regulatory penalties could also be applied.
In addition to that, the exposure to exploitation and scams could drive customers off the platform. That’s why this needs to withstand just about any failure scenario we throw at it.
The challenges of building a customer screening system
Building a system based around a stream of events flowing over Kafka has its benefits, but there are implications to consider. We can’t, for instance, have our topic partitions blocked for any reason. If this happened, it would stop the current customer from being onboarded, and everyone after them.
In building our platform, we brainstormed all the things that could cause this to happen and put countermeasures in place to deal with each scenario. Here are the key measures that were considered…
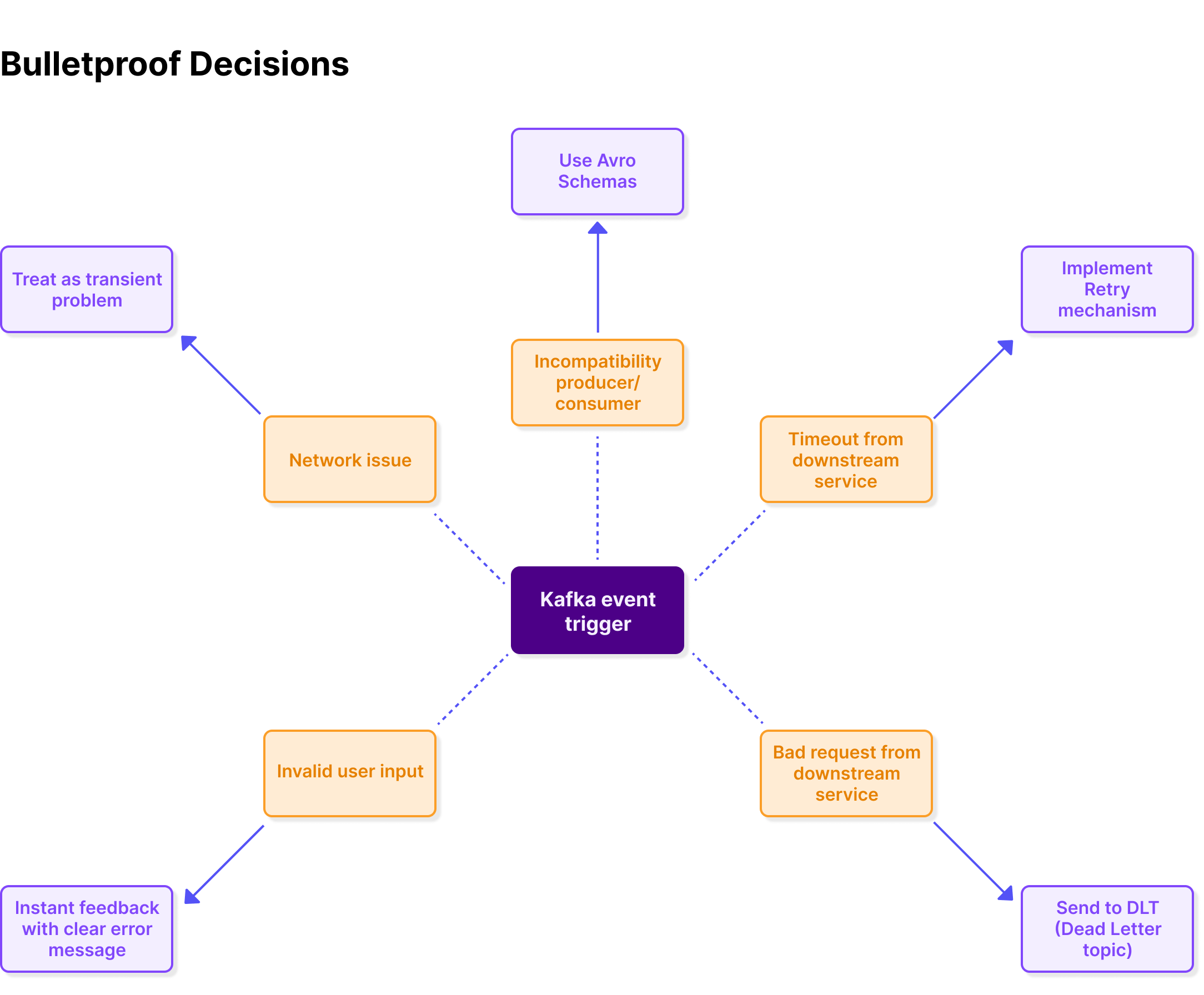
We went ahead and implemented everything that was needed with very few issues. By the end of it, we felt relieved that everything looked good and safe.
The problem with Kafka Consumers
Issues began to emerge from the woodwork when we opened up our onboarding topic to the wider platform. After a few days, several teams started using our topic to invoke the customer screening process for various reasons. Sometime later, we noticed a huge consumer lag on one of the partitions. Everything was blocked and our system couldn’t process anything. We believed we had considered all scenarios and applied countermeasures. How could anything go wrong?
During our investigation, we discovered that one of our Kafka Consumers was stuck trying to process a record, but failed each time during deserialization, hence not incrementing the partition offset. So, when the consumer returned for the next record, it continuously fetched the dud record it couldn’t interpret.
"As long as both the producer and the consumer are using the same compatible serializers and deserializers, everything works fine.
Compatible serializers and deserializers are the key.You will end up in a poison pill scenario when the producer serializer and the consumer(s) deserializer are incompatible. This incompatibility can occur in both key and value deserializers."
Handling Kafka poison pills
The way Spring Kafka deals with this sort of error by default is through a handler called SeekToCurrentErrorHandler which logs consumption errors that occur in the container layer and then skips to the next offset. However, this handler cannot cope with deserialisation exceptions and will enter an infinite retry loop. To fix this, consumers can use a different handler called ErrorHandlingDeserializer. This would be configured to deserialize keys and values by delegating the processing to the original deserializers being used. In our case, these were UUID for Keys and Avro for values.

To override the default behaviour of just logging the error, a custom implementation of the Spring Kafka interface ConsumerRecordRecoverer can be created.

This should be plugged back into the SeekToCurrentErrorHandler when configuring the container factory.